中财投资网(www.161588.com)2026/2/27 11:28:14讯:
AI大模型的快速发展对网络提出超大带宽、超低时延、超高稳定性以及超大规模组网等需求。传统TCP/IP机制因数据需要经过操作系统内核多次复制与协议栈处理,导致CPU资源被网络协议开销占用,并引发通信时延抖动,难以满足AI大模型训练对低时延与大带宽的严苛要求。而RDMA(Remote Direct Memory Access,远程直接存储器访问)技术可通过绕过操作系统内核实现主机间内存直接访问,有效降低多机多卡通信时延,因此成为智算时代高性能网络解决方案。
实现RDMA的方式有IB(InfiniBand,无限带宽)、RoCE(RDMA over Converged Ethernet,基于以太网的远程直接内存访问协议)、iWARP(Internet Wide-Area RDMA Protocol,互联网广域RDMA协议)三种[1]。其中,iWARP是基于TCP/IP的RDMA技术,受TCP影响,该技术性能稍差;IB与RoCE作为主流解决方案,为应对AI大模型时代的挑战提供了关键技术路径。
本文聚焦智算网络的高性能传输需求,重点研究IB、RoCE两种智算网络技术及智算网络典型组网方式,并以RoCE技术为例给出智算网络组网方案,旨在为智算网络的规划和建设提供参考。
1 智算网络组网技术方案1.1关键技术1.1.1IB网络
IB架构由IBTA(InfiniBand Trade Association,InfiniBand贸易联盟)于1999年发布,其核心技术包括远程直接存储器访问的零拷贝技术和内核旁路技术[2],通过这两项技术可显著降低数据传输时延。作为一种面向高性能计算的计算机网络通信标准,IB采用交换式架构,设计之初便支持RDMA,并从硬件层面保障可靠传输,可实现计算机之间、服务器与存储系统之间、存储系统之间的数据流转,同时也是人工智能领域中GPU服务器的首选网络互连技术。
IB网络具备低时延、大带宽、高可扩展性与高吞吐量的显著优势:它依托RDMA零拷贝技术降低系统开销;支持数十Gbit/s甚至更大的带宽,满足大规模数据传输、并行计算等场景需求;可灵活配置全局互连、树状、扁平等多级拓扑结构,还能实现多子网互连,满足大规模计算集群与数据中心的扩展需求;同时凭借低时延与大带宽的特性,支持大规模数据流并行传输。不过该技术需要配套使用支持IB的网卡和交换机,存在成本较高的缺点。
1.1.2RoCE网络
RoCE是一种基于以太网的远程直接内存访问协议,旨在通过以太网网络实现高性能、低时延的数据传输,由IBTA于2010年提出,有RoCE v1和RoCE v2两个版本,目前的主流协议是RoCE v2,该协议作为一种基于RDMA的协议,继承了RDMA的优势,并在以太网方面进行了优化。
RoCE的核心原理是通过规避传统TCP/IP协议栈的多次上下文切换与数据拷贝,并依托RDMA技术让服务器经网卡直接读写远程主机内存,全程无需操作系统内核介入,从而显著降低数据传输时延与CPU资源占用率;相较于传统TCP/IP数据传输方式,RoCE能够高效解决超大规模数据中心的内部通信瓶颈,助力服务器间数据高速流转。
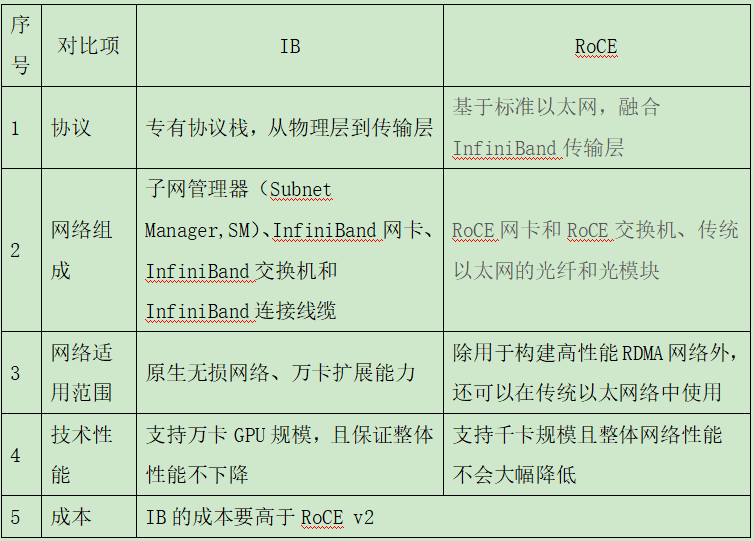
1.1.3IB与RoCE的技术对比
IB和RoCE均为面向RDMA的高性能交换协议。IB完全依赖专用硬件,从硬件层面确保了网络的低时延和高吞吐量;RoCE则将RDMA技术应用于以太网,通过PFC(Priority Flow Control,优先级流量控制)和ECN(Explicit Congestion Notification,显式拥塞通知)等协议实现无损传输。两者在性能、适用规模、成本和供应方面存在显著差异,详见表1。
表1IB与RoCE技术对比
1.2组网架构基于大模型大规模分布式训练与推理的超高吞吐量、超低时延、高可靠性组网需求,智算中心典型组网架构如图1所示,分为参数面、样本面、带内网络和带外网络四个部分。
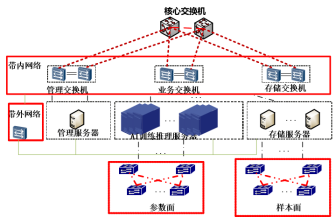
图1智算中心典型组网架构
参数面:承担AI模型训练与推理的参数同步聚合,常采用RDMA及无损组网技术支撑大规模分布式训练,参数面网络应满足规模、吞吐量、可靠性、智能运维等核心技术要求。
样本面:样本面网络负责传输训练的原始与预处理数据,承载计算节点访问存储的流量,通常采用两层CLOS组网架构,接入层为1:1无收敛组网,按需配置算存比,且须满足高可靠性要求。
带内网络:承担系统业务调度与带内管理流量,采用多层CLOS组网架构,为TCP/IP有损网络,要求具备高可靠性。
带外网络:承担服务器、交换机、防火墙等的带外管理流量。带外网络的性能要求低于训练网络,一般无需部署无损网络。
2 智算组网案例本文以某智算私有云建设项目为例,说明RDMA网络在智算组网中的应用,该案例为满足用户DeepSeek-V3/R1(671B)模型和DeepSeek-R1Distill Llama-70B的模型部署需求,共建设8台64卡GPU国产推理服务器,采用RoCE技术组网。
参数面设计:采用200G接入、400G互联的RoCE组网,Spine-Leaf两层胖树架构,采用带宽1:1无收敛设计。单台AI服务器配置8块GPU,8×200G RoCE光口,上行至2台参数面RoCE Leaf交换机;Spine交换机独立部署,Leaf交换机采用400G链路双上联至Spine交换机。
样本面设计:存储交换网采用100G RoCE组网,考虑到资源池规模较小,因此采用单层组网架构及带宽无收敛设计。
带内网络:采用Spine-Leaf组网架构,配置一对管理交换机、一对业务交换机、一对存储交换机,没有无损网络要求。
带外网络:配备2台千兆电口交换机,分别进行带外管理接入,上行接入25G管理业务交换机,最后统一通过核心交换机对外交换数据。
该项目的部署可为社会提供22.4PFLOPS算力,加快相关行业DeepSeek部署和应用推广。
3 结论随着AI大模型对算力和数据交换需求的不断增长,目前智算网络组网技术正在经历快速创新与迭代,IB网络不仅具备高阶在网计算能力,而且拥有大规模资源池部署案例丰富、网络性能与稳定性强的优势;而对于需要快速扩展的分布式存储或中小规模AI推理集群,RoCE网络可通过现有以太网实现低时延、高吞吐量。未来,随着AI大模型向更大规模参数、更高训练效率方向演进,智算网络也将朝着更大带宽、更低时延、更加智能的方向发展。
参考文献
[1]李家清,王祎玮,李道通.智算中心IB及RoCE网络技术探究[J].电信工程技术与标准化,2024,37(1):42-47.
[2]陈岩,张斌,吴海涛,等.智算网络组网技术综述[J].通信技术,2025,58(9):923-931.